Database Partitioning and Sharding
Database partitioning is fundamental in distributed systems. It divides data into partitions that can be independently stored, managed, and queried.
Why Partition?
Section titled “Why Partition?”- Capacity: Fit data when a single machine’s storage/compute is not enough.
- Performance: Restrict queries to relevant partitions; reduce IO.
- Maintainability: Operate on subsets (backup, reindex) without impacting entire dataset.
- Cost and Compliance: Keep hot vs. cold data on appropriate hardware.
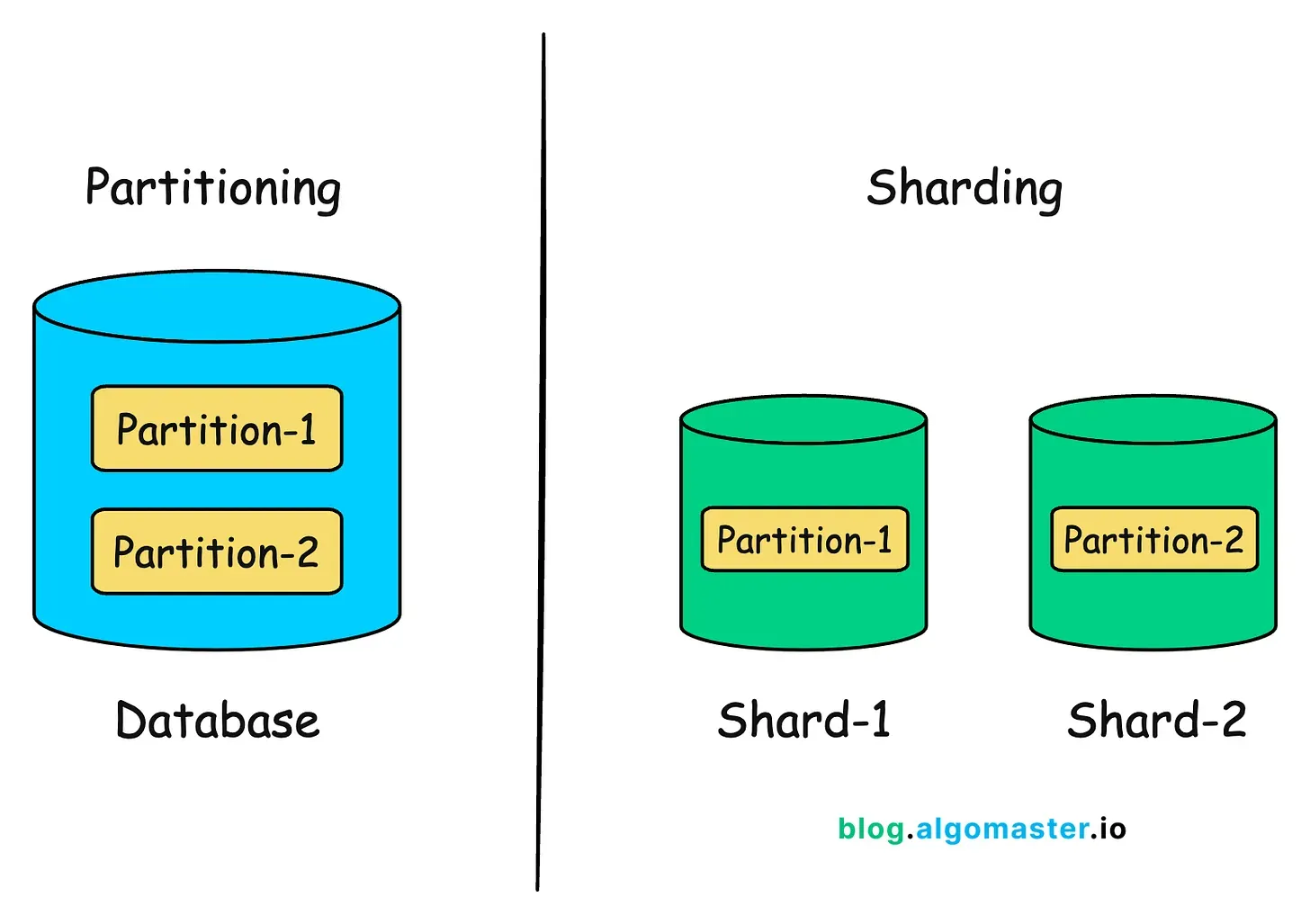
Partition vs. Shard
Section titled “Partition vs. Shard”| Concept | Scope | Deployment |
|---|---|---|
| Partitioning | Splitting data within one logical database instance | Same server (logical splits) |
| Sharding | Distributing partitions across multiple servers | Scale-out (multi-node) |
Partitioning Strategies
Section titled “Partitioning Strategies”Horizontal Partitioning
Section titled “Horizontal Partitioning”Rows are divided based on a partition key.
- Great for scaling linearly with data volume.
- Choose keys that evenly distribute load (avoid hotspot partitions).
Vertical Partitioning
Section titled “Vertical Partitioning”Columns are split across tables, keeping the same primary key.
- Useful when some columns are cold/large (BLOBs) or require extra security.
- Increases join complexity when recombining column groups.
Horizontal Partition Techniques
Section titled “Horizontal Partition Techniques”| Technique | How it Works | Pros | Cons |
|---|---|---|---|
| Range | Split by continuous ranges (dates, IDs) | Easy to reason about | Risk of uneven load if ranges skew |
| List | Explicit values per partition (regions, categories) | Intuitive mapping | Rebalancing when categories change |
| Hash | Hash function on key distributes rows | Even distribution automatically | Harder to control locality |
| Composite | Combine strategies (e.g., range + hash) | Balances locality + distribution | More complex routing logic |
Sharding Deep Dive
Section titled “Sharding Deep Dive”Sharding places partitions on separate servers (shards). Each shard is a self-contained DB node storing a subset of data.
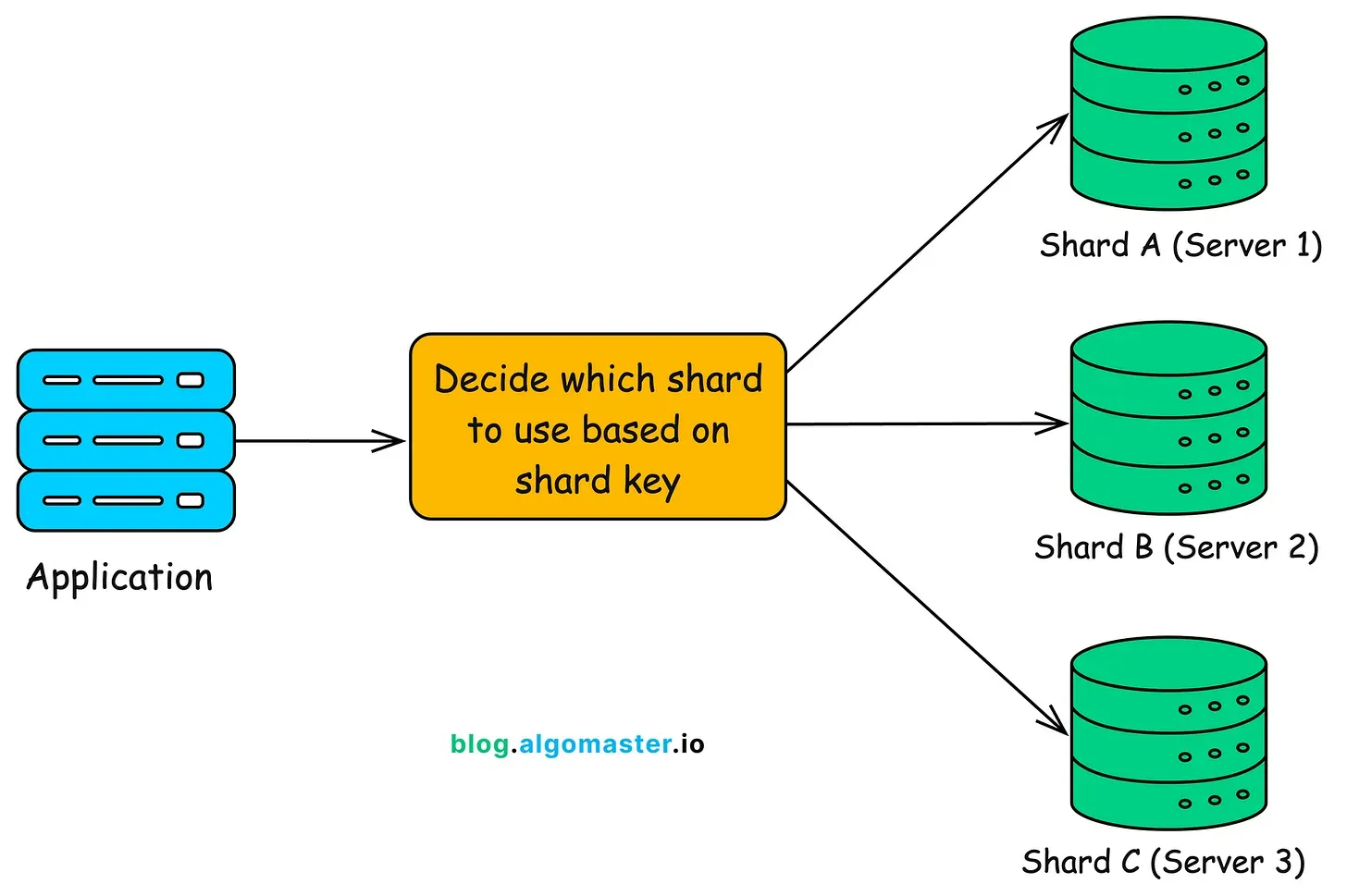
Components
Section titled “Components”- Shard key: attribute(s) determining shard placement (user_id, tenant_id).
- Router/metadata: service that maps keys to shard addresses.
- Shard replicas: optional replication within each shard for HA.
Example
Section titled “Example”- Shard A:
user_id1-25M ->db-shard-a.company.com - Shard B:
user_id25-50M ->db-shard-b.company.com - Router maps
user_idto shard; applications query the correct node.
Common Challenges
Section titled “Common Challenges”- Cross-shard joins: expensive; often replaced by denormalization or application-side joins.
- Referential integrity: foreign keys across shards are not enforced by the DB; ensure in code.
- Rebalancing: adding shards requires moving data; plan for consistent hashing or directory services.
- Hotspots: poor shard keys can overload a single shard; monitor and adjust.
Operational Tips
Section titled “Operational Tips”- Automate shard metadata updates; avoid manual routing tables.
- Monitor per-shard metrics (CPU, disk, query latency) to catch imbalances.
- Design schema with sharding in mind; keep related data co-located by the shard key.
- Consider geo-partitioning to keep data near users and satisfy data residency laws.
- Partitioning: Logical splits within a database for manageability and performance.
- Sharding: Distributing partitions across nodes for horizontal scalability.
- Key decisions: Choose shard keys carefully, plan for rebalancing, handle cross-shard operations in application logic.
- Combine with Database Replication for high availability within each shard.