CAP Theorem Explained
Core Guarantees
Section titled “Core Guarantees”| Guarantee | Definition | Notes |
|---|---|---|
| Consistency | Every read returns the most recent write (or errors). | Differs from ACID consistency; refers to linearizable reads. |
| Availability | Every request receives a non-error response, regardless of staleness. | Clients always get a reply. |
| Partition Tolerance | System continues operating despite message loss or delays between nodes. | Realistic distributed systems must assume partitions. |
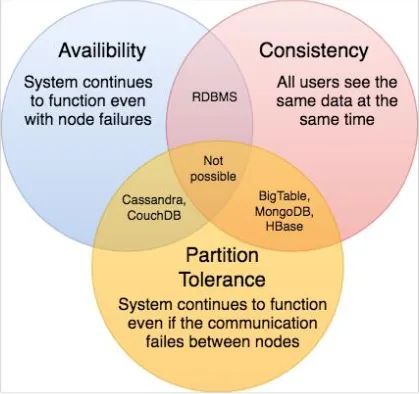
Choosing During a Partition
Section titled “Choosing During a Partition”| Combination | What you keep | What you sacrifice | Typical Systems |
|---|---|---|---|
| CP | Consistency + Partition tolerance | Availability | Banking, stock trading, critical configuration stores |
| AP | Availability + Partition tolerance | Consistency | Social feeds, DNS, shopping carts |
| CA | Consistency + Availability | Partition tolerance | Only feasible in single-node or tightly coupled clusters |
Example Walkthrough
Section titled “Example Walkthrough”- Consistency-first: three-node cluster requires acknowledgements from all nodes before serving reads. On partition, isolated nodes reject requests.
- Availability-first: nodes continue serving reads/writes locally even when disconnected, accepting stale data for uptime.
- Partition tolerance: regardless of strategy, the cluster keeps functioning in the presence of lost or delayed messages.
Consistency Modes
Section titled “Consistency Modes”| Level | Description | Use Cases | Example Technologies |
|---|---|---|---|
| Weak consistency | No guarantees on reads; best effort replication. | Realtime media streams, gaming. | VOIP, multiplayer servers. |
| Eventual consistency | Data converges over time; replicas sync asynchronously. | Social apps, DNS, email. | DynamoDB, Cassandra, DNS. |
| Strong consistency | Reads always reflect the latest writes; synchronous replication. | Financial systems, ledgers. | RDBMS, ZooKeeper, Spanner (with scoped latency). |
Real-World Example
Section titled “Real-World Example”Consider a system with three nodes (A, B, C):
Scenario 1: Consistency
Section titled “Scenario 1: Consistency”- All nodes (A, B, C) maintain the same data
- When B updates data, it must propagate to A and C
- System ensures all nodes show same data or returns error
Scenario 2: Availability
Section titled “Scenario 2: Availability”- If node B fails, A and C continue operating
- System keeps responding to requests
- May not have most recent data
Scenario 3: Partition Tolerance
Section titled “Scenario 3: Partition Tolerance”- Network partition separates B from A and C
- System continues functioning despite partition
- May sacrifice either consistency or availability