Bloom Filter Essentials
Overview
Section titled “Overview”- Maintains a fixed-length bit array and
kindependent hash functions. - Supports
addandpossibly containschecks in constant time. - No deletions in the basic form; removing items requires counting filters or rebuilds.
How It Works
Section titled “How It Works”- Insert: run the element through each hash function and set the corresponding bit positions to
1. - Query: recompute the hashes; if any bit is
0, the element is definitely absent. If all are1, it may exist.
Example
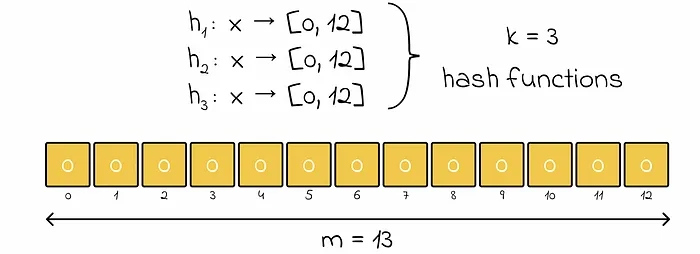
Section titled “Example”- Bit array length (
m) = 13 - Hash functions (
k) = 3
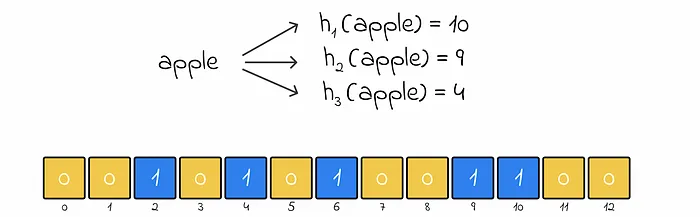
Adding "banana" sets bits [6, 2, 9] to 1. Adding "apple" sets [10, 9, 4]. Checking "orange" hits a 0 bit, so it is definitely absent.
Search
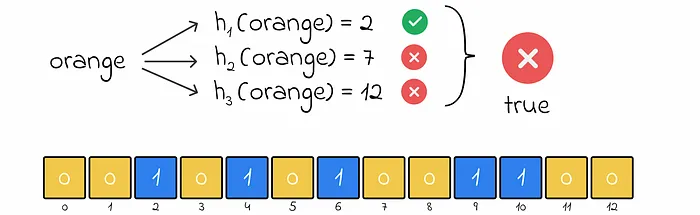
Section titled “Search”- Checking “orange”:
- Hash values: 7, 12
- Bit array: Positions 7 and 12 are 0, so “orange” is not in the set.
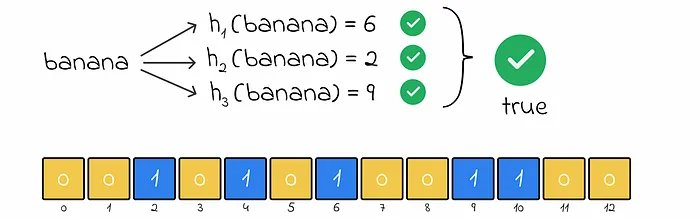
- Checking “banana”:
- Hash values: 6, 2, 9
- Bit array: Positions 6, 2, and 9 are all 1, so “banana” might be in the set.
Nevertheless, the Bloom filter can produce a false positive response when an object does not actually exist but the Bloom filter claims otherwise. This happens when all hash functions for the object return hash values of 1 corresponding to other already inserted objects in the filter.
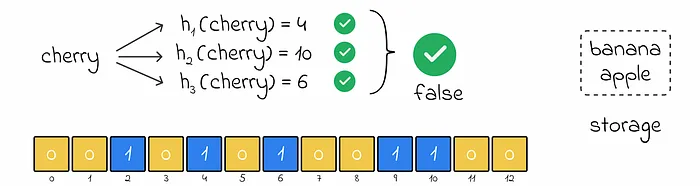
False Positives & Tuning
Section titled “False Positives & Tuning”- Occur when multiple items set the same bit positions.
- Probability rises as the filter fills up; manage load factor (
n, number of inserted items) relative tom. - Reduce false positives by increasing
m, increasingk, or limitingn.
| Parameter | Effect |
|---|---|
Larger bit array (m) | Lowers collision rate, more memory. |
More hash functions (k) | Improves accuracy until diminishing returns; typically k ≈ (m/n) ln 2. |
Fewer items (n) | Keeps filter sparse and accurate. |
Implementation Sketch (JavaScript)
Section titled “Implementation Sketch (JavaScript)”class BloomFilter { constructor(size, hashCount) { this.size = size; this.hashCount = hashCount; this.bits = new Array(size).fill(0); }
hash(item, seed) { let hash = 0; for (const ch of item) { hash = (hash << 5) - hash + ch.charCodeAt(0); hash |= 0; // keep 32-bit } return Math.abs(hash + seed * 31) % this.size; }
add(item) { for (let i = 0; i < this.hashCount; i++) { this.bits[this.hash(item, i)] = 1; } }
mightContain(item) { for (let i = 0; i < this.hashCount; i++) { if (this.bits[this.hash(item, i)] === 0) return false; } return true; }}
// Example usageconst size = 100; // Choose the size of the bit arrayconst hashCount = 3; // Choose the number of hash functions
const bloomFilter = new BloomFilter(size, hashCount);
// Adding items to the filterconst itemsToAdd = ['dog', 'cat', 'bird'];itemsToAdd.forEach(item => bloomFilter.add(item));
// Testing if items might be in the filterconst testItems = ['dog', 'cat', 'bird', 'fish', 'horse'];testItems.forEach(item => { if (bloomFilter.check(item)) { console.log(`'${item}' is probably in the set.`); } else { console.log(`'${item}' is definitely not in the set.`); }});When to Use
Section titled “When to Use”- Fast cache-miss checks (e.g., CDN, database read-through caches).
- Prevent expensive lookups for definitely absent keys.
- Deduplication in streaming pipelines.
Key Takeaways
Section titled “Key Takeaways”- Space-efficient membership checks with configurable false positive rate.
- Requires well-distributed hash functions and pre-sized parameters.
- Monitor fill ratio; rebuild or expand when false positives trend upward.