Caching Fundamentals
Overview
Section titled “Overview”- Cache data that is read frequently, expensive to recompute, or slow to fetch from origin storage.
- Key goals: reduce round-trips, minimize database load, and improve perceived responsiveness.
- Cache capacity is limited and costly—focus on high-value datasets.

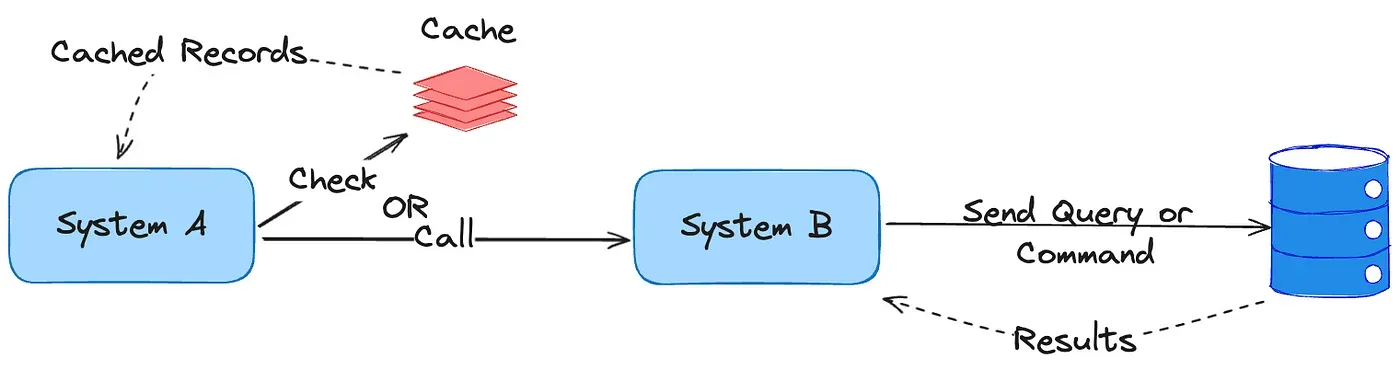
Request Flow 🔁
Section titled “Request Flow 🔁”- Client issues a read.
- Cache lookup executes:
- Cache hit → return data immediately.
- Cache miss → fetch from source of truth, populate cache, and return.
- Eviction policies decide what stays in cache when capacity is reached.
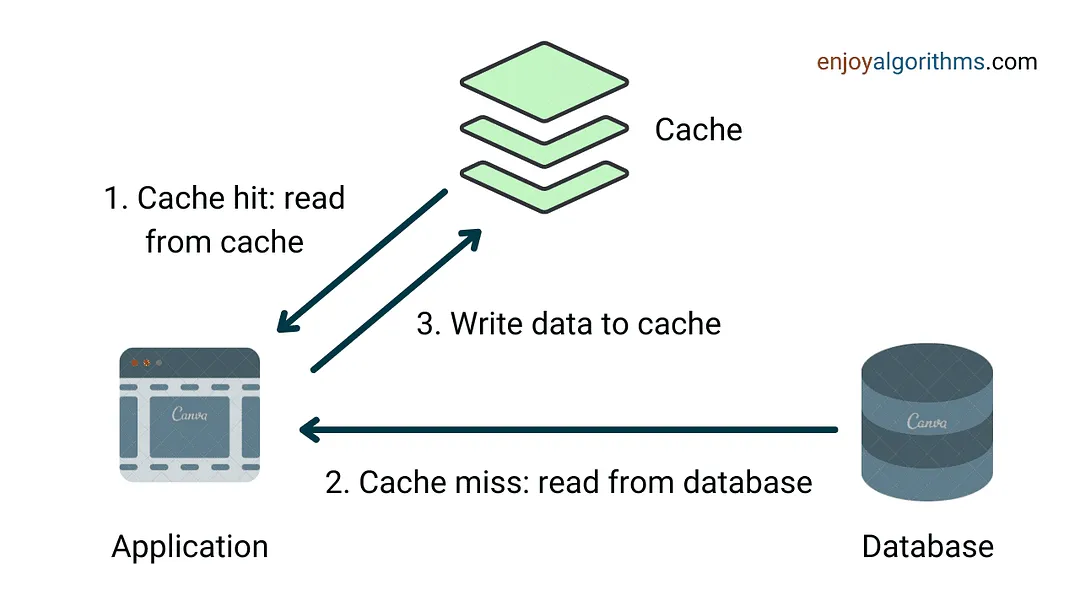
Real-World Usage
Section titled “Real-World Usage”- Web browsers: store static assets (HTML, CSS, JS, images) on disk.
- CDNs: cache static and streaming content near users.
- DNS resolvers: cache domain-to-IP mappings for quick lookups.
Eviction Policies 🧹
Section titled “Eviction Policies 🧹”| Policy | When it helps | Trade-offs |
|---|---|---|
| LRU (Least Recently Used) | Temporal locality | Simple, widely supported |
| LFU (Least Frequently Used) | Stable access patterns | More metadata to track |
| FIFO (First-In First-Out) | Simple queue semantics | Ignores recency/frequency |
| MRU (Most Recently Used) | Bursty workloads | Rarely ideal |
| TTL (Time-to-Live) | Keep data fresh | Requires correct expiry windows |
| Random Replacement | Low overhead | Non-deterministic outcomes |
Invalidation & Refresh
Section titled “Invalidation & Refresh”- Write-through, write-behind, and cache-aside patterns (see Caching Strategies) keep cache contents aligned with the source of truth.
- TTLs prevent stale data from lingering indefinitely.
- Manual invalidation hooks are essential after bulk updates or schema changes.
Benefits ✅
Section titled “Benefits ✅”- Lower read latency and improved user experience.
- Higher throughput using existing infrastructure.
- Reduced load on primary databases or services.
- Enables limited offline or degraded-mode operation for cached resources.
Limitations ⚠️
Section titled “Limitations ⚠️”- Staleness or inconsistency if invalidation is mishandled.
- Cold-start latency while caches warm up.
- Limited improvements for write-heavy workloads.
- Additional operational complexity (evictions, replication, cache coherence).