MapReduce Primer
Concept Overview
Section titled “Concept Overview”- Map phase: transform input splits into intermediate
<key, value>pairs. - Shuffle phase: group identical keys and route them to reducers.
- Reduce phase: aggregate or combine values per key to produce final output.
- Framework (Hadoop, Spark map stage, etc.) handles parallelism, fault tolerance, retries, data locality.
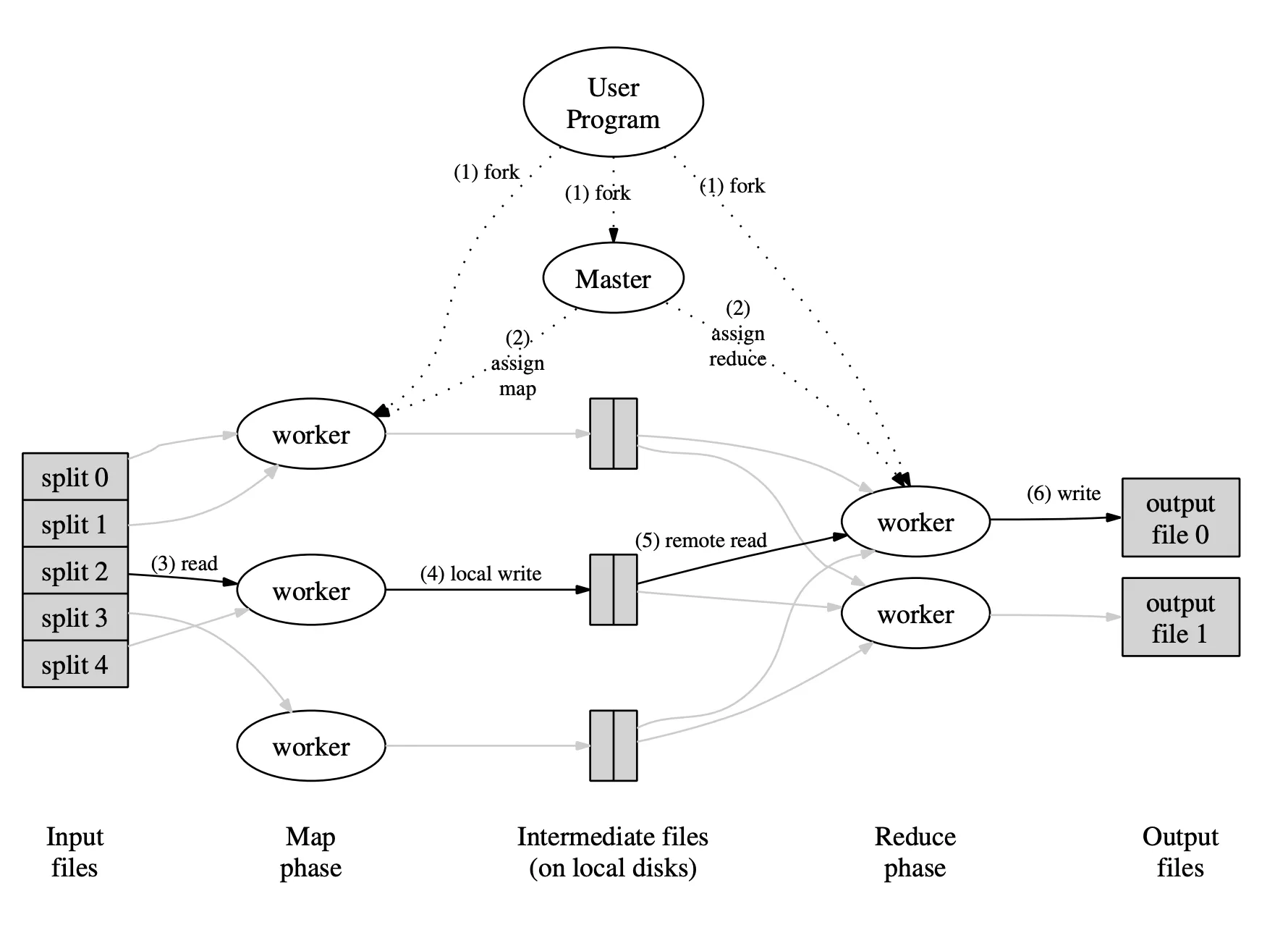
Execution Flow
Section titled “Execution Flow”- Input splitting – large file broken into blocks, distributed to mappers near the data (data locality).
- Map tasks – user-defined
map()emits intermediate pairs. - Partition/shuffle – keys hashed to reducers; framework sorts and transfers data.
- Reduce tasks –
reduce()receives each key and iterable of values; writes results. - Output – stored back in distributed filesystem (e.g., HDFS).
Sample Use Case: Word Length Categorization
Section titled “Sample Use Case: Word Length Categorization”function map(line) { const pairs = []; for (const word of line.split(/\W+/)) { if (!word) continue; const bucket = word.length > 10 ? "moreThan10" : "lessThanOrEqual10"; pairs.push({ key: bucket, value: 1 }); } return pairs;}
function reduce(entries) { const totals = {}; for (const { key, value } of entries) { totals[key] = (totals[key] || 0) + value; } return totals;}Map tasks emit bucketed counts; shuffle groups by bucket; reducers sum counts to produce final tallies.
Advantages
Section titled “Advantages”✅ Parallel processing across nodes
✅ Fault-tolerant (tasks are retried on failure)
✅ Scalable to petabytes of data
✅ Abstraction hides distributed complexities