Master–Slave Replication (Single-Leader Replication)
Master–slave replication (or single-leader replication) is a database replication model in which one node (the master) handles all write operations, while one or more slaves replicate the data for read scalability, fault tolerance, and disaster recovery.
Architecture
Section titled “Architecture”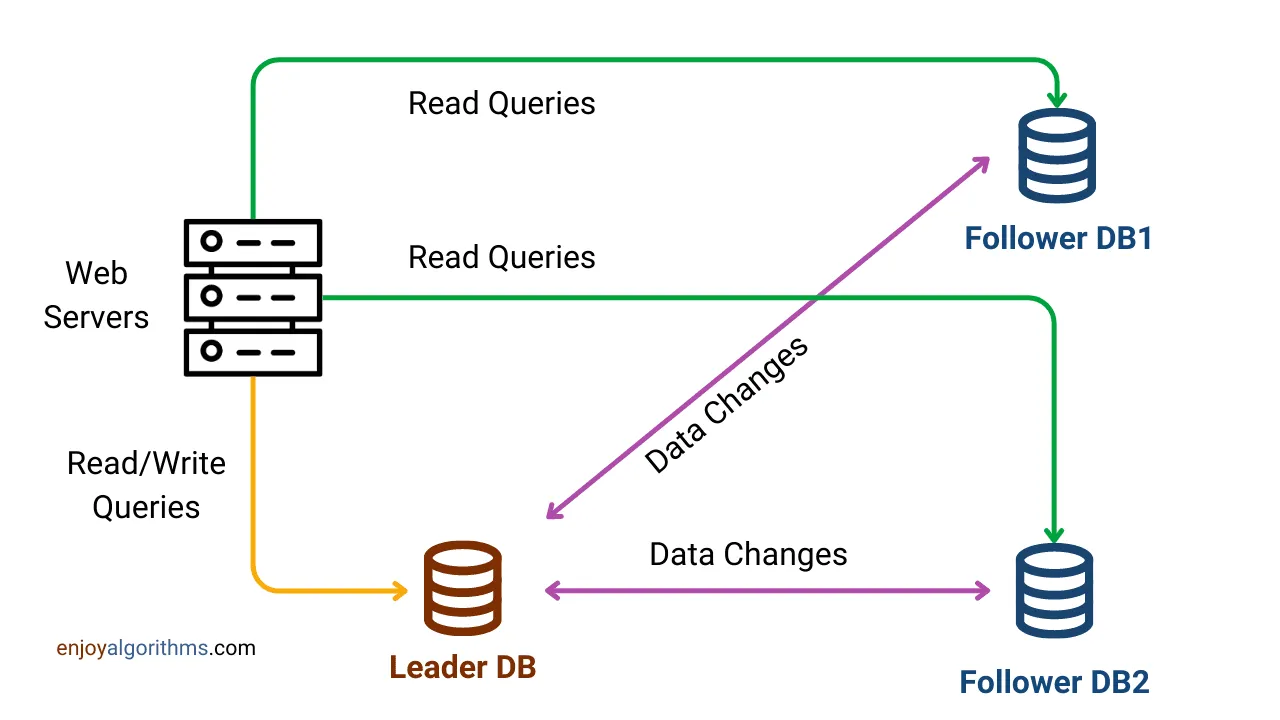
Master Node
- Accepts all write operations (
INSERT,UPDATE,DELETE). - Maintains the authoritative copy of data.
- Produces a replication log (binlog) that records every change.
Slave Nodes
- Continuously replicate the master’s data by reading its binlog.
- Handle read queries to offload the master.
- Can be promoted to master during failover.
Replication Flow
- The master writes data and appends it to the binlog.
- Slaves read and apply changes in the same order.
- This ensures eventual data consistency between nodes.
Key Use Cases
Section titled “Key Use Cases”- Read Scalability → distribute read queries across many followers.
- Fault Tolerance → slaves act as hot/cold standbys.
- Disaster Recovery → replicate to another region or data center for recovery.
Replication Modes
Section titled “Replication Modes”Synchronous Replication
Section titled “Synchronous Replication”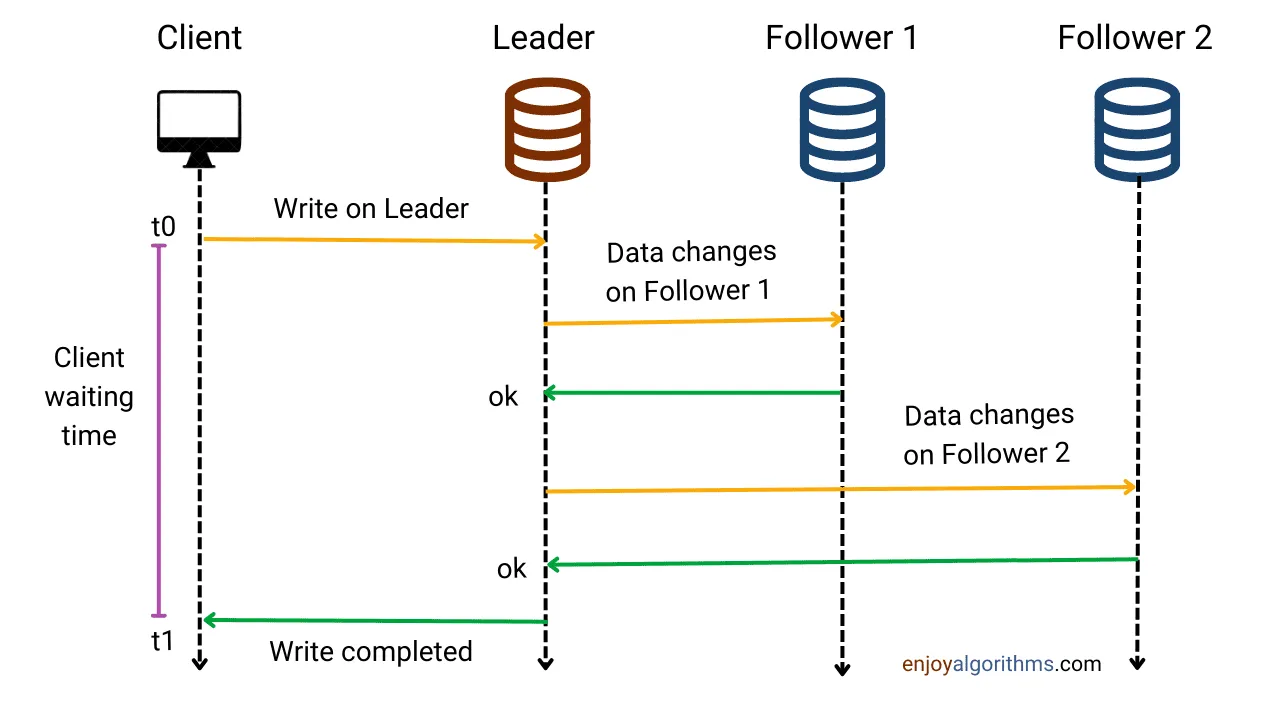
- The master waits for all slaves to confirm a write before acknowledging success.
- ✅ Pros: Strong consistency (no data loss).
- ❌ Cons: Higher latency; slower throughput.
- 💡 Use case: Banking or payment systems needing guaranteed consistency.
Asynchronous Replication
Section titled “Asynchronous Replication”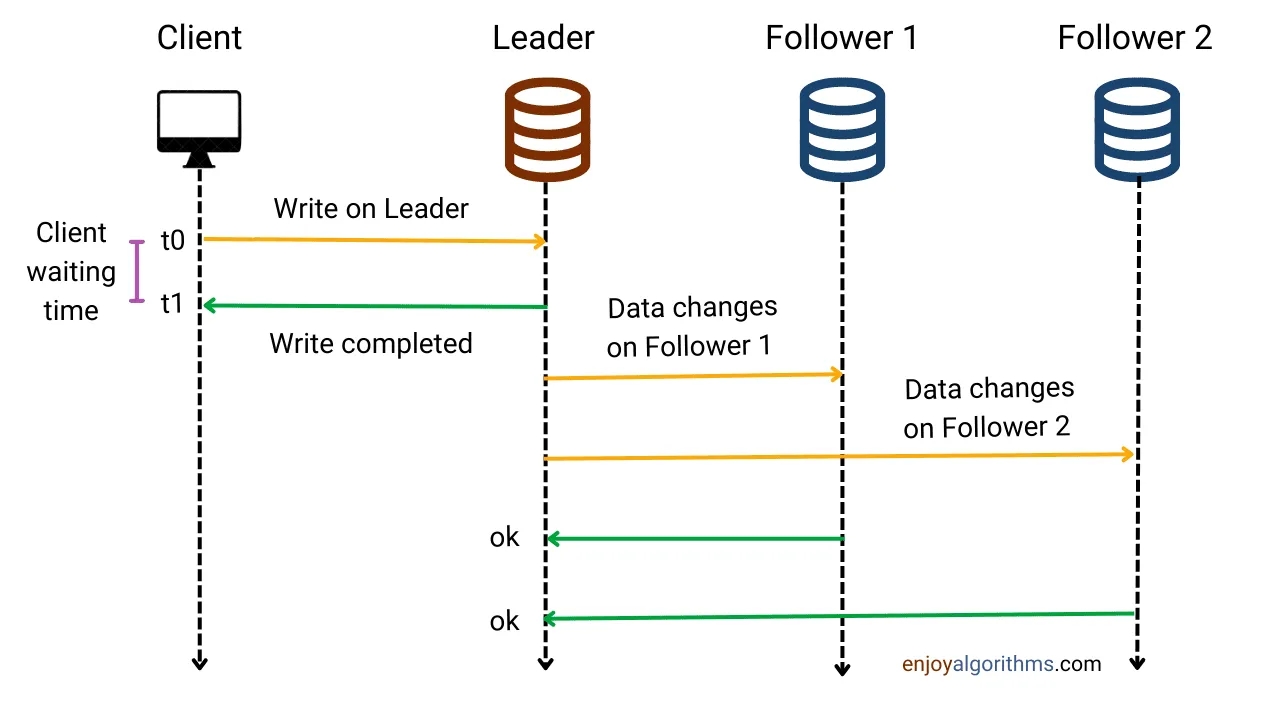
- The master immediately acknowledges the write; slaves catch up later.
- ✅ Pros: Low latency, fast writes.
- ❌ Cons: Possible data loss if master fails before slaves sync.
- 💡 Use case: High-throughput systems prioritizing performance.
Semi-Synchronous Replication
Section titled “Semi-Synchronous Replication”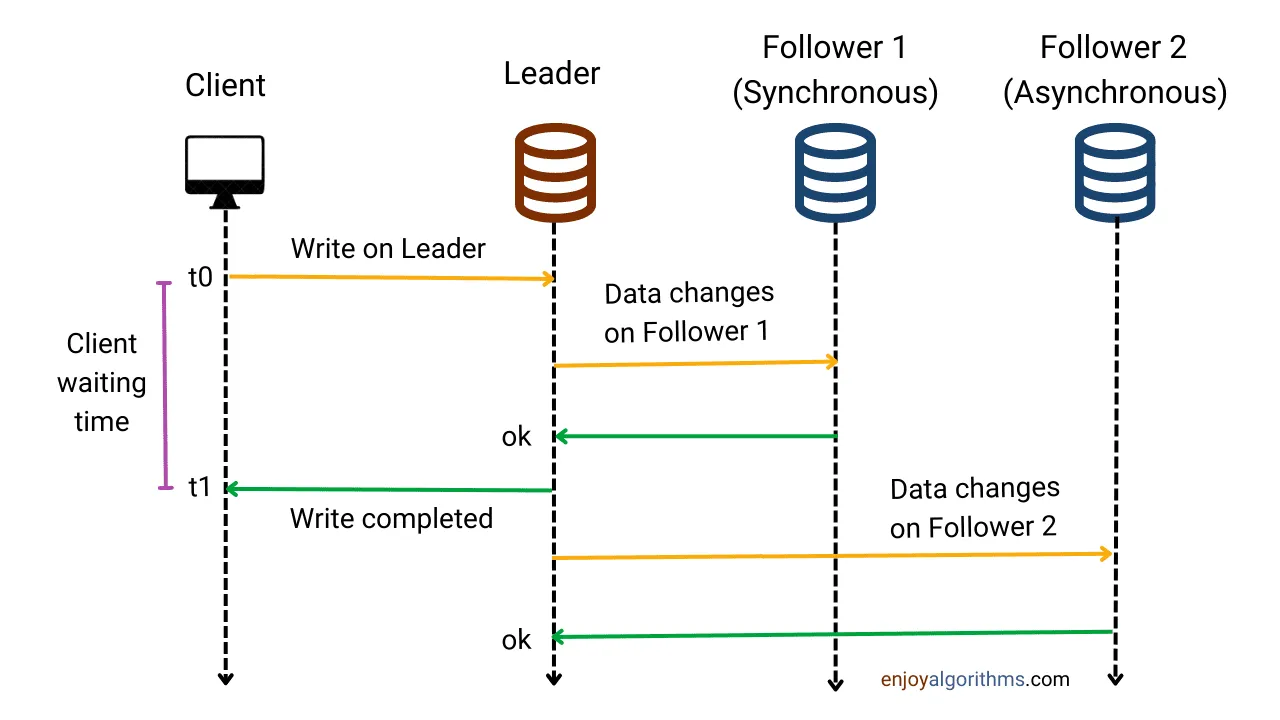
- Hybrid model: one designated slave confirms writes synchronously; others replicate asynchronously.
- ✅ Pros: Balances consistency and performance.
- ❌ Cons: Slightly higher latency than full asynchronous.
- 💡 Use case: Web-scale systems where partial consistency is acceptable but data loss must be minimized.
Handling Node Failures
Section titled “Handling Node Failures”Follower Failure
Section titled “Follower Failure”- The follower reconnects after downtime.
- Requests all missed binlog entries from the master.
- Catches up and resumes replication automatically.
Leader (Master) Failure
Section titled “Leader (Master) Failure”- Detection: Monitored via heartbeats or timeouts.
- Failover:
- Promote the most up-to-date slave as new master.
- Reconfigure other nodes to follow it.
- Challenges:
- Data loss risk if the new master lacks the last transactions.
- Split-brain issues if multiple nodes claim to be master simultaneously.
Adding or Replacing Followers
Section titled “Adding or Replacing Followers”Steps to add a new follower safely:
- Take a consistent snapshot of the master’s data.
- Load the snapshot on the new node.
- Sync it from the snapshot’s binlog position.
- Once caught up, direct read traffic to it.
Comparison Table
Section titled “Comparison Table”| Replication Type | Advantages | Disadvantages |
|---|---|---|
| Synchronous | Strong consistency, zero data loss. | High latency, slower performance. |
| Asynchronous | Fast writes, low latency. | Possible data loss on master crash. |
| Semi-Synchronous | Balanced consistency & performance. | Slight latency overhead. |
Summary
Section titled “Summary”| Feature | Master Node | Slave Node |
|---|---|---|
| Role | Handles writes | Handles reads, backup |
| Data Source | Original copy | Replica of master |
| Failure Role | May cause failover | Can be promoted |
| Typical Count | 1 (active) | Many (replicas) |
Benefits
Section titled “Benefits”- Horizontal read scaling.
- Improved availability and disaster recovery.
- Supports failover for high availability.
Drawbacks
Section titled “Drawbacks”- Write bottleneck (single master).
- Potential replication lag.
- Requires careful failover management to prevent split-brain.